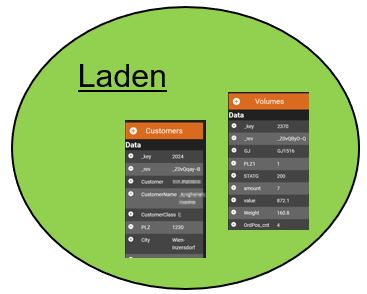
Laden
Die Daten sind vorbereitet und als csv-File vorhanden.
Jede einzelne Datei kann vom PC hochgeladen werden.
Tabellen- und Spaltennamen, Trennzeichen und Formate sind einstellbar, sodass die Daten auch interpretiert werden können.
Diese Konfiguration kann gespeichert werden („instructions“).
in intoData :
Aus csv-Dateien mit Spaltenüberschriften ->
werden Datentabellen zur Weiterverarbeitung
Aus der Vorbereitung der Daten liegen csv-Dateien vor, ganz unabhängig von der Quelle. Diese Daten werden nun geladen, intoData legt die Daten – für den Benutzer nicht sichtbar – in einer Datenbank ab. Dabei entsteht die Basis für eine Datenstruktur.

Die Daten werden geladen aus csv-Dateien, die Formatierung von Feldern (z.B. Datum) uä. ist einstellbar.
Dieser Schritt ist autom. wiederholbar, z. B. für veränderte Daten.
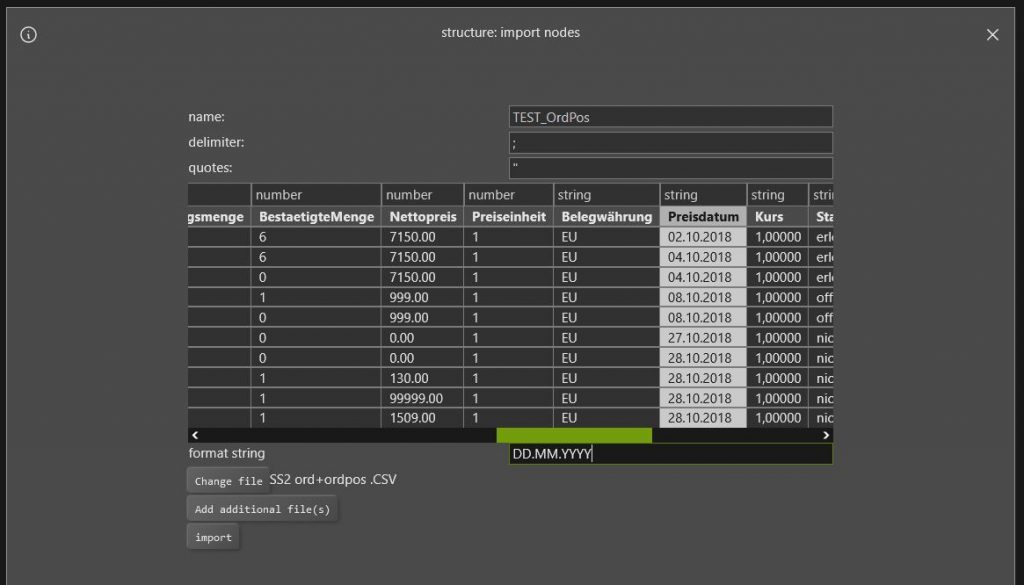
Laden von Datentabellen – „nodes“ and „edges“
Die vorliegenden Quelldateien werden ins System übernommen.
Eine Datei wird ausgewählt und analysiert.
Die Spaltenformate können angegeben werden.
Mehrere gleich strukturierte Files können in einem Zug geladen werden.

Das Ergebnis kann über den Strukturgraph dargestellt werden:
Die geladen Daten werden in die Struktur übernommen.
Strukturierungsfunktionen stehen zur Verfügung
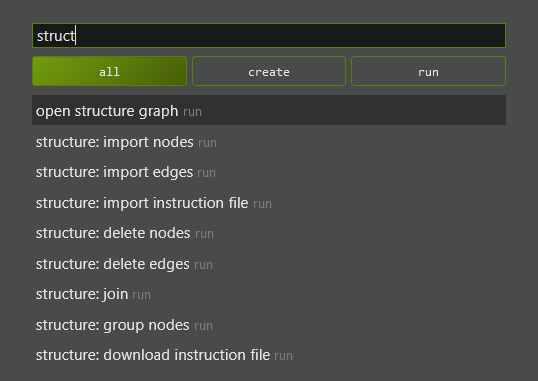
Mehr dazu unter Strukturieren

Wiederholtes Laden – auch mit neuen Datenfiles gleicher Struktur
Beim Aufbau einer Struktur werden die durchgeführten Schritte und die verwendeten Datenfile aufgezeichnet.
Es entsteht ein „instruction“-file, kann:
… gespeichert werden
.. editiert w (Klartext, JSON) und verteilt werden
… für eine Wiederholung wiederverwendet werden.
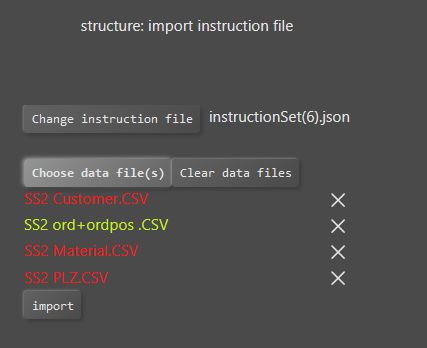
Instruction file kann gewählt werden :
Benötigt Datendateien werden aus dem File ermittelt
Die eigentliche Datenquelle = Datei mit den Spalten kann seperat gewählt werden.
Damit ist eine Korrektur an Quelldaten erfolgen und ein Neuladen in der definierten Struktur einfach durchgeführt werden.

Es kann eine neue Datenbank angelegt und geladen werden – unabhängig von der intodata Installation an der die Struktur erstellt wurde.